
业务流程
- 审查材料上传 (pdf、word、png等)
- 材料解析,使用Mineru进行解析提取
- 材料的审查主题提取,依靠编写的提示词,使用大模型提取json格式的主题信息
- 根据主题信息匹配excel表格内的审查标签和提示词
- 使用匹配到的提示词和材料解析后的内容调用大模型生成审查结果

工作流主要节点
提取解析结果
Dify内置Mineru插件提取材料的结果主要有两个,一个是string类型的text,另一个是名为content_list的json数组,两个输出结果的示例如下。
{
"text": "字节跳动2026校园招聘深圳大学城宣讲会\n\n9月16日18:30
\n\n北京大学深圳研究生院国际会议中心(J栋)\n\n# 来宣讲,强势助攻拿
Offer\n\n# 现场聊\n\n现场与业务Leader、HR零距离交流 心仪业务全貌、求
职秘籍一手掌握 校招HR一对一,流程咨询、简历辅导 一站解决\n\n火面试直通
卡\n\n# 现场发\n\n$\\bar { }$ 多个职类、多个业务现场双选\n\n有机会获取“
面试直通卡”“机会 $+ 1$ 卡”\n\n$^ { \\ast }$ “机会+1”卡:有机会从已终止的流
程中,被邀请至新岗位\n\n# 现场抽\n\n多轮惊喜大奖,抽出好运锦鲤字节跳动定制伴手礼先到
先得\n\n\n\n# 扫码立即报名\n\n\n\n# 深圳大学城\n\n9月16日18:30北京大学深圳研究生院国际会议中心(J栋)",
"files": [],
"json": [
{
"content_list": [
[
{
"page_idx": 0,
"text": "字节跳动2026校园招聘深圳大学城宣讲会",
"type": "text"
},
{
"page_idx": 0,
"text": "9月16日18:30",
"type": "text"
},
{
"image_caption": [],
"image_footnote": [],
"img_path": "images/f79b3799affe794d6cdb864a2cc5f250d3c029b9396e43c5adf7f41d55041160.jpg",
"page_idx": 0,
"type": "image"
},
{
"page_idx": 0,
"text": "扫码立即报名 ",
"text_level": 1,
"type": "text"
},
{
"image_caption": [],
"image_footnote": [],
"img_path": "images/a4da1dfaedb539e9ef0d5dfbba7f16e40c3eb9d217b3c4ff261192d59b27e610.jpg",
"page_idx": 0,
"type": "image"
}
]
]
}
],
}可以看到解析结果中的text字段包含大量无效信息,有换行符、图片链接等,这些信息对于后续的大模型分析材料都是无用的,如果直接使用text字段信息会造成token浪费并且分析效果也不好。同时注意到content_list这部分信息,依据其中的type字段可以分离出真正需要的文本内容。
因此提取解析结果节点就是一个代码节点,提取出content_list中的text类型的文本内容,具体代码十分简单,不再赘述。
主题分析
主题分析关系着最终的审查结果,主要分析的是审查规则和提示词的excel文件中需要的主题,编写提示词使得大模型对材料内容进行设定的主题进行分析。
该节点是一个LLM节点,需要关心的主要是提示词的编写。主题分析一个重点中模型是否能正确分析主题的属性,这与实际设定的主题有关,要针对主题来考虑。值得注意的是,上传材料的解析结果是否有足够的信息来让大模型判断主题的属性。由于后续进行规则匹配是强规则的,主题分析的结果需要是一个json格式的输出。所以提示词的另一个重点是如何使得大模型输出格式化的json结果。关键有两个,一是给出输出示例以供模型参考,二是使用特定分隔符以分割开无效内容和格式化内容
给出输出示例即给出一个输入和输出对示例来让模型遵从格式进行输出,使用特性分隔符来分割内容可能并不需要,因为在前期搭建工作流时使用的大模型时qwen-plus,Dify内置的qwen模型并没有提供qwen-plus的think关闭参数,调用时会将思考过程的内容也一并输出,所以需要使用分隔符来分割思考部分的内容,如果可以设定think参数则不需要这个分隔符。后续的提取json就是依靠分隔符提取出json数据
匹配审查标签
标签规则表是一个excel文件,主题分析的结果是json数据,这里利用pandas库来让主题分析的结果来匹配标签规。具体的代码也十分简单,不再展示。需要注意的是,Dify内置的代码节点并没有pandas库,需要更改配置来导入pandas,具体步骤如下。
修改dify代码目录中docker/volums/sandbox/dependencies下的python-requirements.txt,添加pandas库
保存后重启sandbox容器
安装可能需要一定时间,可通过docker logs 查看sandbox容器日志观察安装进度
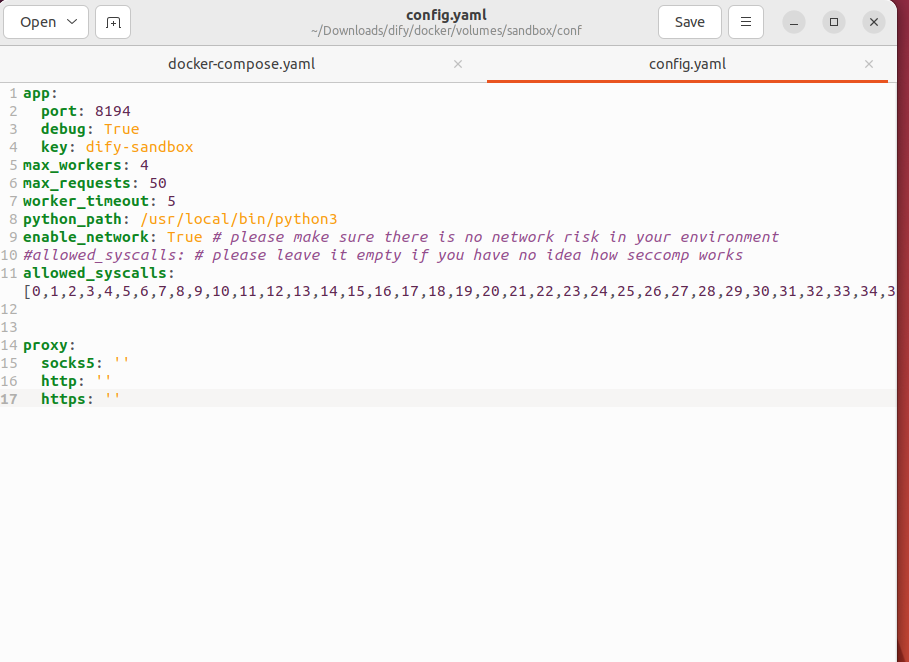
如果要读取文件,还需要更改sandbox的配置文件来提供相应的权限,这里为了方便直接赋予了所有权限,可以按需更改。
在docker/volums/sandbox/conf下的config.yaml文件修改
allowed_syscalls: [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240,241,242,243,244,245,246,247,248,249,250,251,252,253,254,255,256,257,258,259,260,261,262,263,264,265,266,267,268,269,270,271,272,273,274,275,276,277,278,279,280,281,282,283,284,285,286,287,288,289,290,291,292,293,294,295,296,297,298,299,300,301,302,303,304,305,306,307,308,309,310,311,312,313,314,315,316,317,318,319,320,321,322,323,324,325,326,327,328,329,330,331,332,333,334,335,336,337,338,339,340,341,342,343,344,345,346,347,348,349,350,351,352,353,354,355,356,357,358,359,360,361,362,363,364,365,366,367,368,369,370,371,372,373,374,375,376,377,378,379,380,381,382,383,384,385,386,387,388,389,390,391,392,393,394,395,396,397,398,399,400,401,402,403,404,405,406,407,408,409,410,411,412,413,414,415,416,417,418,419,420,421,422,423,424,425,426,427,428,429,430,431,432,433,434,435,436,437,438,439,440,441,442,443,444,445,446,447,448,449,450,451,452,453,454,455,456,457,458,459,460,461,462,463,464,465,466,467,468,469,470,471,472,473,474,475,476,477,478,479,480,481,482,483,484,485,486,487,488,489,490,491,492,493,494,495,496,497,498,499]
迭代审查规则
迭代使用匹配到的提示词与材料解析内容循环调用大模型进行审查,这里需要注意的是,如果有分支结构,保证两个分支都要返回结果,且结构一致。如果一个分支实际不需要返回结果,可以返回一个结构正确的空结果,最后筛去空结果即可。
Streamlit开发前端页面
调用Dify工作流API
搭建完工作流之后,点击发布即可通过API访问当前工作流。查看左侧的访问API页面,可以获取调用工作流API的url和参数类型,以及返回的数据,这里主要关心执行Workflow和上传文件这两个API。
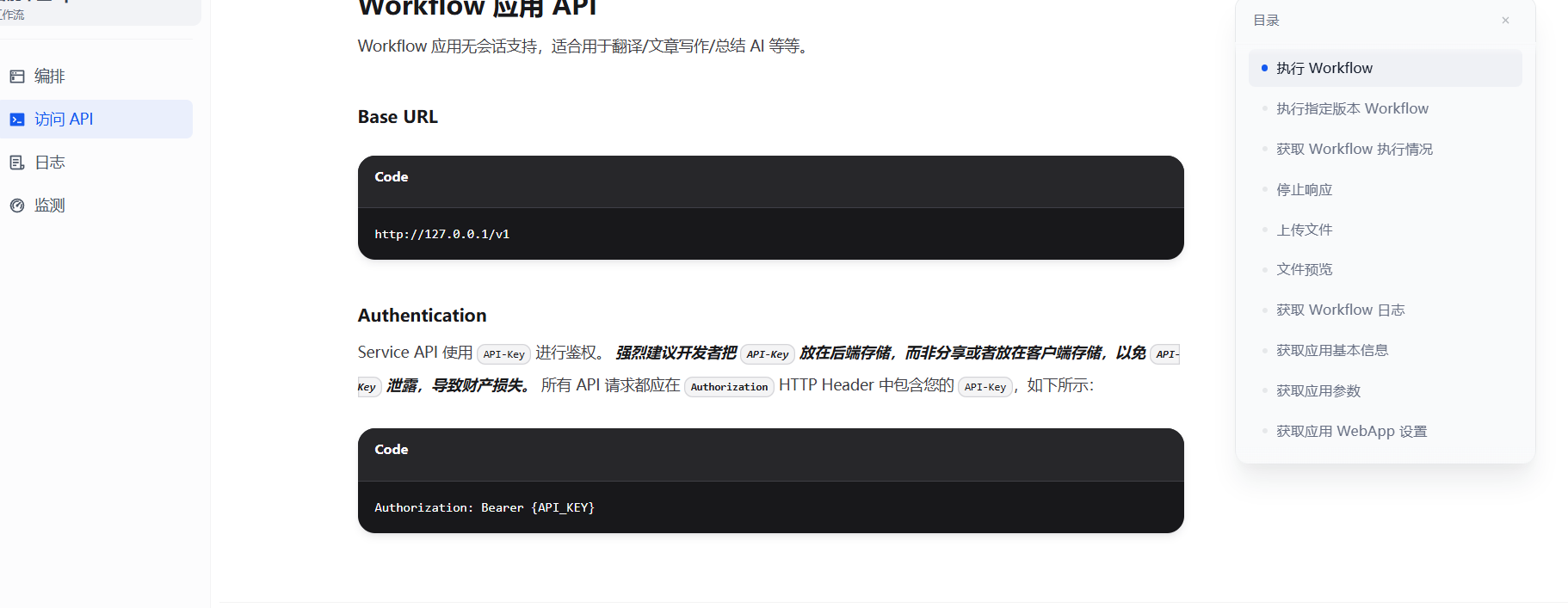
执行Workflow,url为"{base_url}/v1/workflows/run"。需要传递的参数主要有inputs ,response_mode,user ,files (参数包含文件时需要传递)。
response_mode(string) Required 返回响应模式,支持:
streaming流式模式(推荐)。基于 SSE(Server-Sent Events)实现类似打字机输出方式的流式返回。blocking阻塞模式,等待执行完毕后返回结果。(请求若流程较长可能会被中断)。 由于 Cloudflare 限制,请求会在 100 秒超时无返回后中断。
inputs(object) Required 允许传入 App 定义的各变量值。 inputs 参数包含了多组键值对(Key/Value pairs),每组的键对应一个特定变量,每组的值则是该变量的具体值。变量可以是文件列表类型。 文件列表类型变量适用于传入文件结合文本理解并回答问题,仅当模型支持该类型文件解析能力时可用。如果该变量是文件列表类型,该变量对应的值应是列表格式,其中每个元素应包含以下内容:
type(string) 支持类型:
document具体类型包含:'TXT', 'MD', 'MARKDOWN', 'PDF', 'HTML', 'XLSX', 'XLS', 'DOCX', 'CSV', 'EML', 'MSG', 'PPTX', 'PPT', 'XML', 'EPUB'image具体类型包含:'JPG', 'JPEG', 'PNG', 'GIF', 'WEBP', 'SVG'audio具体类型包含:'MP3', 'M4A', 'WAV', 'WEBM', 'AMR'video具体类型包含:'MP4', 'MOV', 'MPEG', 'MPGA'custom具体类型包含:其他文件类型
transfer_method(string) 传递方式,remote_url图片地址 /local_file上传文件url(string) 图片地址(仅当传递方式为remote_url时)upload_file_id(string) 上传文件 ID(仅当传递方式为local_file时)
执行Workflow的response,实际返回的数据在outputs 字段中。
python封装调用DifyAPI逻辑
定义一个DifyAPIClient类封装调用工作流的逻辑,初始化流程如下:
def __init__(self, api_key, user_name="zsh",base_url="http://127.0.0.1"):
self.headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
self.user_name=user_name
self.base_url=base_url
self.api_key=api_key实现上传文件的方法:
def upload_file(self, files):
upload_url=f"{self.base_url}/v1/files/upload"
data={'user':self.user_name}
response=requests.post(upload_url,headers={'Authorization': f'Bearer {self.api_key}'},
files=files,data=data,timeout=300)
if response.status_code in [200,201]:
result=response.json()
print("文件上传成功!文件ID:", result['id'])
return result['id']
else :
print('上传失败')
return None执行Workflow的逻辑:
def run_workflow(self, workflow_inputs, file_id=None,file_type=None, timeout=300,response_mode="blocking"):
"""执行工作流"""
workflow_url = f"{self.base_url}/v1/workflows/run"
# 构建请求数据
data = {
"inputs": workflow_inputs,
"response_mode": response_mode,
"user": self.user_name
}
# 如果有文件,添加到inputs中
if file_id:
data["inputs"]["file"] = {
"type": file_type,
"transfer_method": "local_file",
"upload_file_id": file_id
}
print(f"调用工作流...")
print(f"输入参数: {json.dumps(data['inputs'], ensure_ascii=False, indent=2)}")
#流式调用
if response_mode == "streaming":
response=requests.post(workflow_url, headers=self.headers,
json=data, stream=True, timeout=timeout)
response.raise_for_status()
return response
#阻塞调用
else:
try:
response = requests.post(workflow_url, headers=self.headers,
json=data, timeout=timeout)
if response.status_code == 200:
result = response.json()
print("工作流执行成功!")
return result.get('data', result)
else:
print(f"工作流执行失败: {response.status_code}")
print(f"错误信息: {response.text}")
return None
except requests.exceptions.Timeout:
print("请求超时")
return None
except Exception as e:
print(f" 执行异常: {e}")
return None